Obsidian 入门59:用 Fast Note Sync 自建一套多端同步
昨晚我把 Fast Note Sync 升到了 3.2.2。
服务端备份、二进制替换、启服、验证,五分钟就好。当时我还挺得意。
然后 Mac 端开始报错了。
一打开 Obsidian,插件状态一直显示「服务已断开」。我在 WebGUI 重新生成 token、复制粘贴、点「测试连接」,反复几次,连不上。错误码 463,上传附件会话不存在。
我以为完了。3.2.2 调了 Protobuf 协议,是不是跟客户端 2.1.0 不兼容了?我甚至开始琢磨要不要把服务端回退到 3.2.1。
后来发现,根本不是协议的问题。
是 3.0 的令牌架构换了一套,需要客户端重启整个 Obsidian。
等等,先确认你能不能用
升级的故事讲完了,但别冲动。这一节是劝退章节。如果你没满足这些条件,下面不用看了。
硬条件,AI 帮不了你的:
- ☑️ 一台7×24 在线的机器(云服务器 / NAS / 树莓派 / 旧电脑)
- 云服务器:国内轻量云 1 核 1GB 够用(实测:FNS 占 116MB 内存、0.5% CPU)
- NAS:群晖、威联通、极空间都可(套件或 Docker)
- 树莓派:建议 4GB 内存版(4 代或 5 代都行)
- 旧电脑:装个 Linux 也能跑,但要保证稳定在线
软条件,有 AI 就不算门槛:
以前装 FNS 需要你会 Linux 命令行、SSH、systemd。但在今天,这些已经不是硬性障碍了。你把需求扔给 AI,它能一步步教你。
我自己的用法是:遇到不会的命令,直接截图给 AI 让它解释;配置文件不会写,告诉 AI 我的环境让它生成;出错看不懂日志,复制给 AI 让它诊断。

所以只要你有台服务器,其他的 AI 能帮你填平。
但有一条心理准备我需要说在前面。自管不是 5 分钟装好就完事的,升级可能踩坑,排错需要时间。这不只是技能问题,是你愿不愿意把周末的一两个小时花在这上面。
所谓自管,就是自己管自己,服务端装在你自己的机器上,升级、排错、备份都是你的事。但数据也都在自己掌控之中。
你不适合 FNS 如果:
- ❌ 电脑不 24 小时开机 → 别用。手机端同步会延迟
- ❌ 笔记超过 50GB → 跑得动,但要走对象存储后端,配置更复杂
- ❌ 完全不想碰运维的事 → 回到 入门 58走 RemotelySave 路线,更省心
开头我升级 3.2.2 只花了 5 分钟,那是因为我已经有台跑了一段时间的服务器,流程都跑顺了。自管的「省心」是攒出来的,不是装出来的。
为什么选 Fast Note Sync
总篇 Obsidian 入门57:找到适合自己的多端同步方案 把 8 种方案分成了 4 类。Fast Note Sync 属于「自部署」那一类,跟上一篇文章的云服务路线是两条不同的路。
FNS 最大的特点是实时。你在 Mac 上改完一条笔记,手机端几秒就能收到,体验很接近闭源服务。而且开发很活跃,前两天刚发了新版本,不像有些自建项目半年不更新。
它跟其他方案最大的区别在于数据流向。
- iCloud 和 Obsidian Sync 的数据经过第三方服务器
- Remotely Save + COS 存在云存储上。
FNS 的数据只在你自己的服务器和设备之间流转,不经任何第三方。
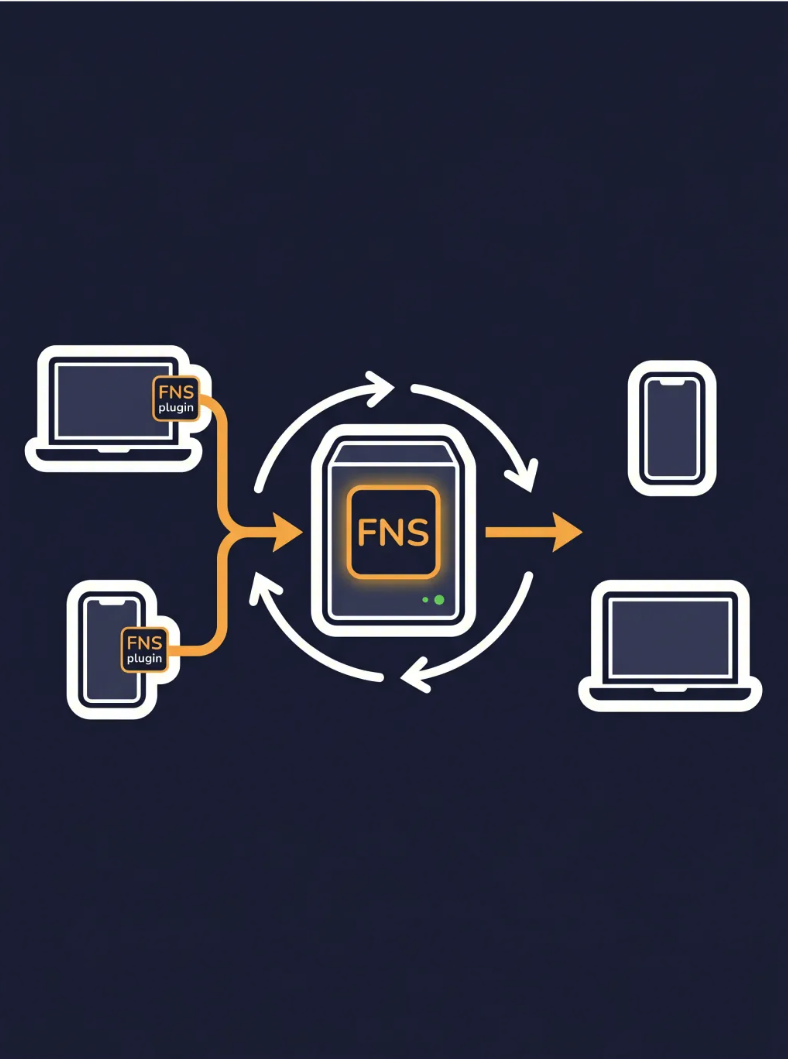
如果你对「笔记在哪」这件事有强烈的主权意识,FNS 是几条路里最彻底的。
所以这条路线不适合所有人。
它适合有服务器、对数据主权有要求、而且不介意周末花点时间折腾的人。如果你不想当运维,我更推荐走上一篇文章的 Remotely Save 路线。
如果你已经拥有一台服务器并且在用 OpenClaw 或者 Hermes,完全可以借助他们的能力帮你在服务器上部署 FNS 的服务端。
完整部署流程
上节说了「自管」的取舍,这节是具体怎么管。
装服务端
方案 A:自购云服务器(最省心)
国内轻量云 1 核 1GB 够用。我的经历的话,我自己跑了几个月了。
我用的是 2 核 2G 的腾讯云轻量服务器,之前在跑 OpenClaw,现在在跑 hermes-Agent。其实我是因为有了要跑 OpenClaw/Hermes 才买的服务器,接着才在服务器上顺手部署了 FNS 的服务端。
一年下来服务器的费用不算贵(我的服务器是 99 元/年,后续续费会比这个价格贵,到时候再取舍了),比买闭源笔记服务的「高级会员」通常还划算。
方案 B:NAS / 树莓派(数据全在本地)
群晖、威联通、极空间都有 Docker 套件。官方有 Dockerfile,基于 Alpine 镜像(~50MB),让 AI 帮忙写个 docker-compose 就行。
方案 C:复用现成机器(最省钱)
如果你已经有一台 24 小时开机的开发服务器,直接装在上面就行。
关键步骤:
- 下载最新服务端二进制:
fast-note-sync-service/releases - 写配置文件
config.yaml(不会写的话,把环境告诉 AI,让它帮你生成一份) - 启动命令
./fast-note-sync-service run -c config.yaml - 进程守护:用
systemd或nohup(同样可以交给 AI,告诉它你用的是什么系统,让它帮你配)
装客户端
- Obsidian → Settings → Community plugins → 搜「Fast Note Sync」
- 配置服务端地址(
http://你的IP:9000) - 在 WebGUI 注册账号 → 把 token 填到客户端(WebGUI的地址,可以让你的 AI 告诉你)
- 重启 Obsidian(第一次也需要重启)
验证同步
- Mac 端新建一条笔记
- 手机端等几秒(3.x 起 Protobuf 协议同步速度更快,手机端也需要安装 FNS的客户端插件)
- 反向验证:手机改 → Mac 收
- 也可以上去服务器的 WebGUI 查看同步上去的文件。
玩一下 WebGUI
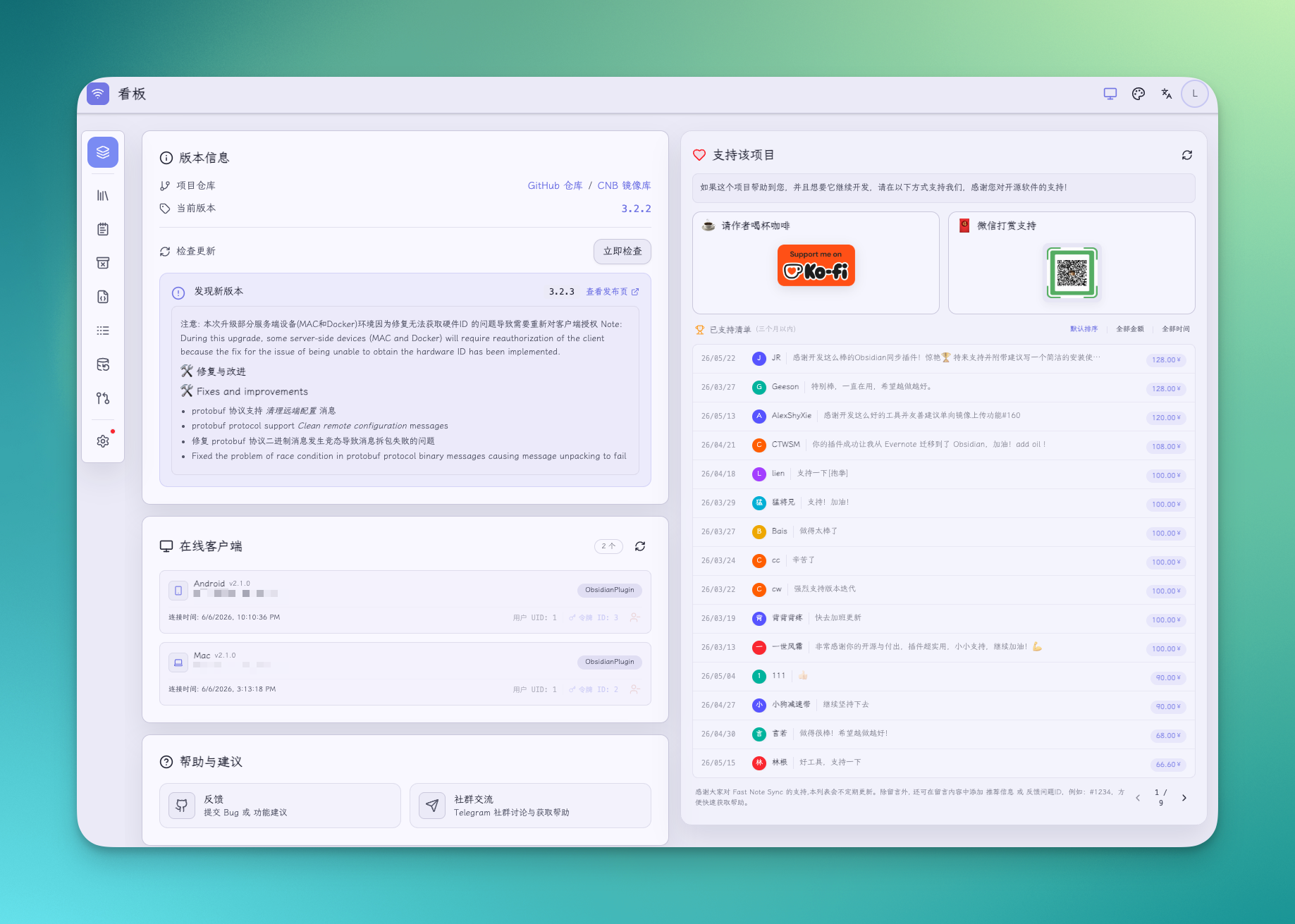
3.x 起内置了 WebGUI(以前要单独部署)。打开 http://你的IP:9000/ 登录,能看:
- 当前连接的设备列表
- 笔记目录浏览
- 令牌管理(3.0 新功能,能单独吊销某台设备的 token)
- 全文搜索(3.2.1 新功能)
差点忘了提,服务端默认监听 9000 端口(HTTP)和 9001 端口(性能监控)。云服务器要在安全组里放行 9000,不然客户端连不上。不知道怎么配安全组?截图给 AI,它告诉你去哪里点。
升级踩坑实战
上一节说「自管 = 你得会点运维」。这一节是具体示范。
下面的步骤全部都是 Hermes 帮我跑的,我只让他去检查现在的服务端版本是多少,然后判断是否要升级。给到升级的指令之后,他就自己去执行了(我配置的是 Minimax m3的模型)!
昨晚升级实录(按时间线):
- 00:26 备份 v2.12.9,115MB 的二进制,命名
fast-note-sync-service-v2.12.9.bak(我之前一直这么命名) - 00:26 下载 3.2.2,62MB 的 tarball,解压 123MB
- 00:26 停服,
kill 834(PID 834,跑了 17 天) - 00:26 替换 + 启动,5 秒内
/api/health返回version: 3.2.2, status: healthy - 00:34 Mac 端报错,30 次 463 错误,80 秒
- 00:35 重启 Obsidian,错误停止
关键教训:
- 3.0+ 升级后必须重启整个 Obsidian,仅重启插件无效
- 现象:插件状态显示「服务已断开」,日志报 463
- 解法:
Cmd+Q退出 Obsidian,重新打开
这不是文档写的,是我试出来的。当然你也可以把日志扔给 AI 让它分析,可能几分钟就定位到了。
3.0 之前的版本升级是「无缝」的。新版本上来,WebSocket 自动接管。
3.0 之后改了「有状态多维度令牌」,需要客户端主动重新建立 WebSocket。客户端 2.1.0 的实现是让你重启整个 Obsidian。

这是「自管」的小代价。
闭源服务升级时你可能也会遇到登录态失效,但通常是点「重新登录」就完事。
自管服务的坑是,没有「重新登录」按钮,要你自己知道是「重启客户端」。
说起来 4 月我也因为「主动推送不可靠」切到过 SyncThing。自管这件事,我自己也反复过。
- 我现在手机和 Mac 同步是用的 Fast note sync
- Mac的 obsidian 和服务器文件同步用的Syncthing
这篇文章讲的是怎么用 Fast Note Sync。但其实我更想说的是:自管这件事,从来不是「装好就完事」。
你选了自建服务端,就要接受:
- 升级是周末可能要做的事(不是「用户无感」的那种)
- 踩坑是必然(每次升级都可能遇到新的)
- 运维知识是慢慢攒的(kill 进程、看 systemd、查日志、读 release notes)。现在有 AI 了,这一步可以把门槛降到很低了
闭源服务的代价是「数据不在你手上」。
自管服务的代价是「你得折腾」。
选哪个,看你更不能接受哪个。
对我来说,我愿意当自己的运维。
至少我知道我的笔记在跑在哪个机器的哪个进程里。
这件事本身,就让我心安。
进阶阅读
- Obsidian 入门57:找到适合自己的多端同步方案,FNS 在 8 方案里的定位
- Obsidian 入门58:用 Remotely Save + 腾讯云 COS 实现多端同步,上一单篇(云服务路线)
- 从 Fast Note Sync 切到 SyncThing:我的 Obsidian 同步终于不用靠 OpenClaw 自由发挥了(4 月),反方视角
- 不写一行代码,让服务器上的 OpenClaw 自动往我的 Obsidian 里塞笔记(2 月),FNS 首次出场
这篇属于 Obsidian 相关教程。想按顺序学习,可以回到完整的 Obsidian 入门教程路径。